
Evolution, Challenges and Considerations of Super-scalar Architecture 超标量架构的变革、挑战和思考
You can get a PDF of this article in ‘Accessing’ section.
您可获取本文章的 PDF。请前往“获取本文章”部分。
Super-scalar Architecture: Evolution, Challenges and Considerations
超标量架构:变革、挑战和思考
1 Introduction
引言
The emergence and evolution of super-scalar architecture has largely influenced the development of the computer field. In this report, we will explore it in three aspects. Firstly, we shall delve into the hardware part, tracing the evolution from single-core to multi-core processors and examining different types of multi-core processors and their developments over the years. Secondly, we will navigate through the operating system, getting to know about the main OSs capable of utilizing the power of multi-core processors, their evolution, and a comprehensive discussion of the features implemented by one OS: Linux. Finally, we will clarify the influence of two critical principles in parallel computing: Amdahl’s Law and Gustafson’s Law. These laws provide invaluable insights into the potential and limitations of parallel processing, shaping our understanding of super-scalar architecture’s future.
超标量架构的出现和演变在很大程度上影响了计算机领域的发展。在本文中,我们将从三个方面对其进行探讨。首先,我们将深入探讨硬件部分,追溯从单核处理器到多核处理器的演变过程,研究不同类型的多核处理器及其多年来的发展。其次,我们将浏览操作系统,了解能够利用多核处理器能力的主要操作系统、它们的演变,以及对一种操作系统所实现功能的全面讨论:Linux。最后,我们将阐明并行计算中两个关键原则的影响: 阿姆达尔定律 (Amdahl’s Law) 和古斯塔夫森定律 (Gustafson’s Law)。这些定律对并行处理的潜力和局限性提供了宝贵的见解,帮助我们理解超标量架构的未来。
2 The Rise of Multi-core Processors and PCs
多核处理器和个人电脑的崛起
2.1 Introduction to Multi-Core Processors and Their History
多核处理器简介及其发展史
Multi-core processors are integrated circuits that contain two or more processing units, or cores. Each core can only operate one single instruction at the same time, however, due to the presence of multiple cores, the processor is able to execute several instructions simultaneously, thus increasing the overall speed on a macro level, resulting in faster and more efficient computing. The concept of ‘multi-core’ was introduced in the 1980s as the improvement of clock speed of ‘single-core’ processors slowed. Multi-core processors gradually entered the commercial field in the early 21st century. The POWER4 Chip launched by IBM in 2001 was the first commercial multi-core processor (Chen et al., 2009).
多核处理器是包含两个或两个以上处理单元或内核的集成电路。每个内核在同一时间只能运行一条指令,但由于存在多个内核,处理器能够同时执行多条指令,从而在宏观上提高了整体速度,使计算速度更快、效率更高。随着“单核”处理器时钟速度的提高,“多核”的概念在 20 世纪 80 年代被提出。21 世纪初,多核处理器逐渐进入商业领域。IBM 于 2001 年推出的 POWER4 芯片是首个商用多核处理器(Chen 等人,2009 年)。
2.2 Types of Multi-Core Processors
多核处理器的类型
2.2.1 Symmetric Multi-Processing
对称多处理器 (SMP)
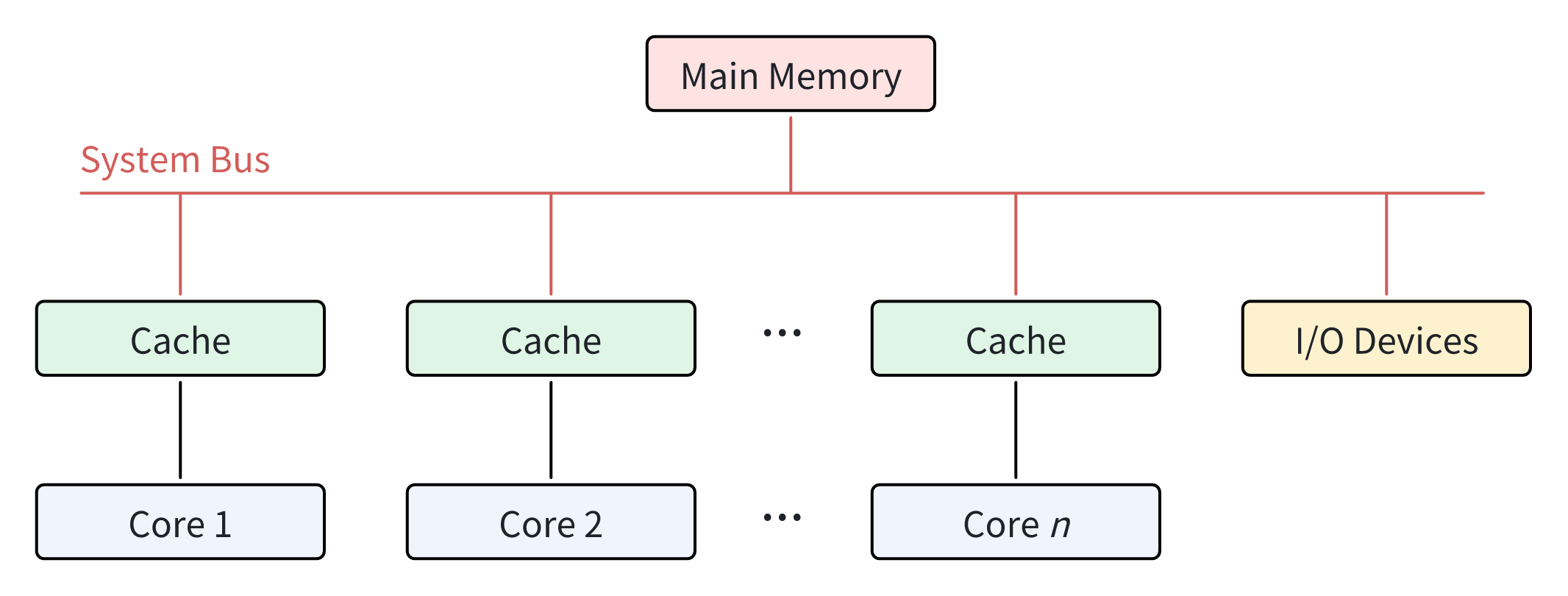
In a SMP-type processor, there is typically one main memory which is shared by all processing units. Each core has equal access to reading from or writing to any memory location, as well as other resources like I/O devices, via system bus. Most multi-core processors in use today use SMP architecture. Figure 1 shows the relationship between the different cores in SMP architecture.
在 SMP 型处理器中,所有处理单元通常共享一个主存储器。每个内核都可以通过系统总线平等地读取或写入任何内存位置以及 I/O 设备等其他资源。目前使用的大多数多核处理器都采用 SMP 架构。图 1 显示了 SMP 架构中不同内核之间的关系。
Advantages of SMP Architecture
SMP 架构的优势
Affordability 经济性
Since there is only one shared main memory and one system bus for all the cores in SMP architecture, SMP-type processors are generally less expensive.
由于在 SMP 架构中,所有内核只有一个共享主内存和一条系统总线,因此 SMP 型处理器的成本通常较低。
Reliability 可靠性
Since each core is relatively parallel in SMP architecture, even if there is a problem with one, the whole system is still able to operate at a reduced speed.
由于在 SMP 架构中,每个内核都是相对并行的,因此即使其中一个内核出现问题,整个系统仍能以较低的速度运行。
2.2.2 Non-Uniform Memory Access
非统一内存访问 (NUMA)
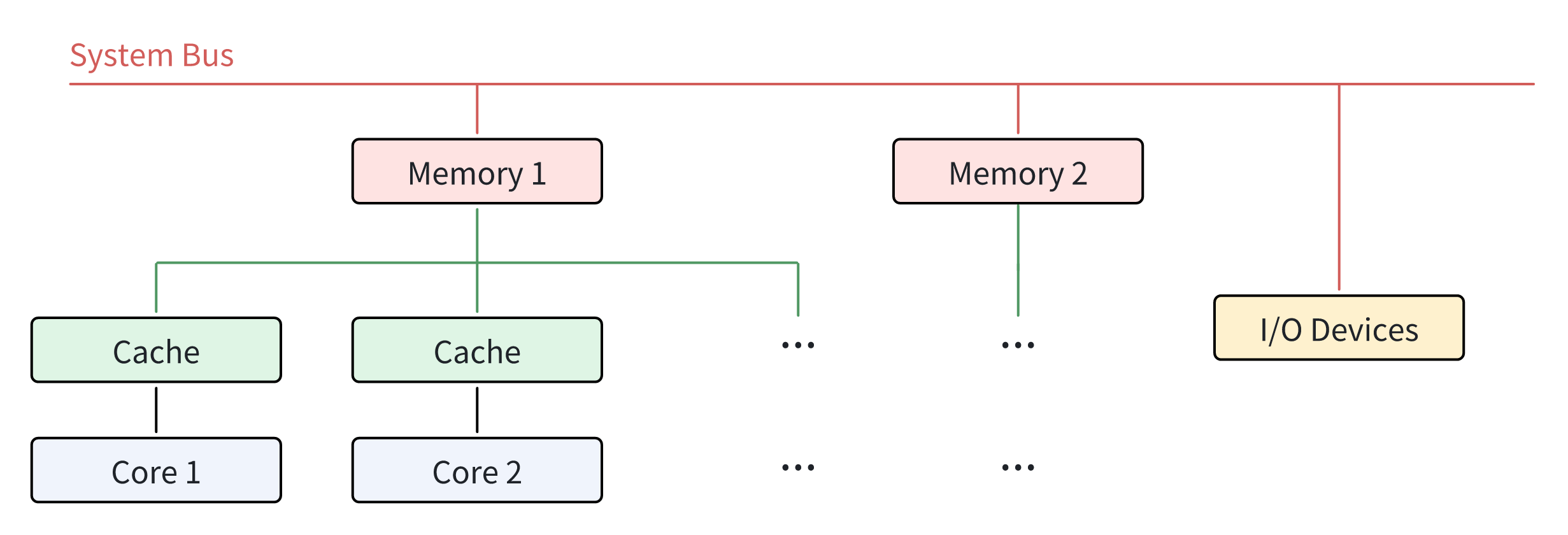
The emergence of NUMA structure is later than that of SMP architecture, because it is a result of optimization based on SMP architecture. In NUMA architecture, unlike SMP architecture, each core typically has its own local memory, or “near” memory, which the core can access with lower latency than other memory nodes, or “far” memory. Multiple cores may share one memory node. This compensates for the fact that memory operates significantly slower than processing units, which means that NUMA-type processors are able to provide better speed and performance than SMP-type processors in scenarios where multiple processing units need to access memory at the same time. NUMA architecture is prevalent in many high-performance computing environments nowadays, for instance, servers and workstations. Figure 2 shows the relationship between the different cores in NUMA architecture.
NUMA 结构的出现晚于 SMP 架构,因为它是在 SMP 架构基础上优化的结果。在 NUMA 架构中,与 SMP 架构不同的是,每个内核通常都有自己的本地内存或称“近”内存,与其他内存节点或称“远”内存相比,内核可以以较低的延迟访问这些内存节点。多个内核可以共享一个内存节点。这弥补了内存运行速度明显慢于处理单元的缺陷,也就是说,在多个处理单元需要同时访问内存的情况下,NUMA 型处理器能够提供比 SMP 型处理器更好的速度和性能。目前,NUMA 架构在许多高性能计算环境中都很普遍,例如服务器和工作站。图 2 显示了 NUMA 架构中不同内核之间的关系。
Advantages of NUMA Architecture
NUMA 架构的优势
Performance 性能
Since every core in NUMA architecture has its own local memory, the memory access times of cores are significantly reduced. This also means that the possible memory contention caused when multiple cores are accessing the memory simultaneously are avoided to the greatest extent, which improves the overall system performance.
由于 NUMA 架构中的每个内核都有自己的本地内存,因此内核的内存访问时间大大缩短。这也意味着可以最大限度地避免多个内核同时访问内存时可能造成的内存争用,从而提高系统的整体性能。
Scalability 可扩展性
NUMA architecture is built for heavy workloads. When more powerful performance is needed, additional cores and their memory nodes can be added to the processor. This proves that NUMA architecture has a strong scalability.
NUMA 架构专为繁重的工作负载而设计。当需要更强大的性能时,可以向处理器添加额外的内核及其内存节点。这证明 NUMA 架构具有很强的可扩展性。
2.3 The Development of Multi-core Processors and Modern PCs
多核处理器和现代个人电脑的发展
After multi-core processors entered the commercial field in the early 21th century, multi-core processors became widely used in consumer PCs. By the mid-2000s, dual-core processors became the mainstream in the PC market.
21 世纪初多核处理器进入商用领域后,多核处理器开始广泛应用于消费类个人电脑。到 2000 年代中期,双核处理器成为 PC 市场的主流。
Around 2010, more advanced quad-core processors began to be adopted in consumer PCs. The advantages of multi-core processors are further reflected, because they will not significantly increase computing energy consumption while further improving the performance of computers.
2010 年前后,更先进的四核处理器开始在消费类个人电脑中应用。多核处理器的优势进一步体现,因为它们在进一步提高计算机性能的同时,不会大幅增加计算能耗。
The 2010s witnessed an explosion in the number of cores in commercial multi-core processors. Hexa-core, octa-core, and even higher-core processors emerged one after another. PCs were beginning to have the ability to perform tasks that were more complex and required more computing power than the past, for instance, running a large-scale video game. Ordinary people began to gain more powerful capabilities with the help of PCs.
2010 年代,商用多核处理器的内核数量激增。六核、八核甚至更高核处理器相继出现。个人电脑开始有能力执行比过去更复杂、需要更强计算能力的任务,例如运行大型视频游戏。普通人开始借助个人电脑获得更强大的能力。
Today, the design of multi-core processors begins to focus more on the optimization for different cores, rather than simply accumulating the number of cores. Cores on every multi-core processors nowadays are becoming more specialized. Take Intel i9-13900H, one of the most powerful multi-core processors in PCs at present, as an example. Figure 3 below (Amazon, 2023) outlines some of the parameters of the chip. As shown, Intel i9-13900H has 14 cores, of which 6 are performance cores, which are optimized for high-performance tasks, and the other 8 are energy-efficiency cores, which are specifically designed for efficiency. This kind of differential design allows PCs to be capable of a wide range of workloads.
如今,多核处理器的设计开始更多地关注不同内核的优化,而不仅仅是内核数量的累积。如今,每款多核处理器的内核都越来越专业化。以英特尔 i9-13900H 为例,它是目前个人电脑中功能最强大的多核处理器之一。图 3(Amazon,2023 年)概述了该芯片的部分参数。如图所示,英特尔 i9-13900H 有 14 个内核,其中 6 个是性能内核(又称 P 核),针对高性能任务进行了优化,另外 8 个是能效内核(又称 E 核),专门为提高效率而设计。这种差异化设计使 PC 能够胜任各种工作负载。

Since the appearance of multi-core processors, the adoption of them in PCs has significantly enhanced of capability of modern PCs. The transformation of modern PCs has also led to the development of more sophisticated operating systems designed to make the most use of the parallel processing capabilities of multi-core processors. This will be covered in the next chapter.
自从多核处理器出现以来,在个人电脑中采用多核处理器大大提高了现代个人电脑的性能。现代个人电脑的变革也促使人们开发出更复杂的操作系统,以充分利用多核处理器的并行处理能力。此内容将在下一章中介绍。
3 Operating Systems
操作系统
3.1 The Importance of Operating System Support for Multi-core Processors
操作系统支持多核处理器的重要性
Resource Utilization
资源利用率
The operating system plays a important role in managing resources for different cores in a multi-core processor. Without the effective support of an operating system, the resources of a multi-core processor may not be properly utilized. The operating system is responsible for task scheduling, ensuring that each core is effectively utilized and that no core is idle while others are overloaded. This balance is critical in achieving high performance. Additionally, the operating system manages the memory hierarchy, ensuring that each core has the same access to memory resources, which is important for efficient execution of tasks.
操作系统在管理多核处理器中不同内核的资源方面发挥着重要作用。没有操作系统的有效支持,多核处理器的资源可能无法得到合理利用。操作系统负责任务调度,确保每个内核都得到有效利用,确保没有内核闲置,而其他内核超负荷运行。这种平衡对于实现高性能至关重要。此外,操作系统还负责管理内存层次结构,确保每个内核都能访问相同的内存资源,这对高效执行任务非常重要。
Scalability
可扩展性
As the number of cores in a processor increases, the complexity of managing these cores and their interactions also increases. The operating system must be capable of scaling its management capabilities to accommodate the increased number of cores. Without a scalable operating system, the benefits of adding more cores could be limited by the increased overhead of managing them, thereby limiting the potential performance improvements.
随着处理器内核数量的增加,管理这些内核及其交互的复杂性也随之增加。操作系统必须能够扩展其管理能力,以适应内核数量的增加。如果没有一个可扩展的操作系统,增加内核的好处可能会因为管理内核的开销增加而受到限制,从而限制了潜在的性能提升。
Parallelism and Concurrency
并行性和并发性
Parallelism and concurrency are inherent advantages of multi-core processors, allowing multiple tasks to be executed simultaneously. However, this requires sophisticated support from operating system. It is responsible for managing concurrent tasks, ensuring that they are executed without conflicts and that the results are correctly synchronized. Furthermore, the operating system must also manage parallelism, dividing tasks into smaller subtasks that can be executed in parallel across multiple cores. This requires complex algorithms for task division and scheduling, as well as for managing communication and synchronization between cores.
并行和并发是多核处理器的固有优势,可以同时执行多个任务。然而,这需要操作系统的精密支持。操作系统负责管理并发任务,确保这些任务在执行过程中不发生冲突,并正确同步执行结果。此外,操作系统还必须管理并行性,将任务划分为更小的子任务,以便在多个内核上并行执行。这就需要复杂的算法来进行任务划分和调度,以及管理内核之间的通信和同步。
3.2 The History and Development of Multi-core Utilization in Main OSs
主要操作系统多核利用的历史与发展
Today, the most common mainstream operating systems in our lives, including Linux, Windows and macOS, are all well supported with multi-core processors.
如今,我们生活中最常见的主流操作系统,包括 Linux、Windows 和 macOS,都能很好地支持多核处理器。
Linux
Linux began its support for SMP architecture in its version 2.0 in 1996. It introduced LinuxThreads as a partial implementation for POSIX threads, which is a thread standard for Portable Operating System Standard, or POSIX. With the introduction of POSIX threads, Linux was able to support user-level threading, enabling parallel task execution.
Linux 从 1996 年的 2.0 版本开始支持 SMP 架构。它引入了 LinuxThreads 作为 POSIX 线程的部分实现。POSIX 线程是可移植操作系统标准(Portable Operating System Standard,简称 POSIX)的线程标准。引入 POSIX 线程后,Linux 能够支持用户级线程,实现并行任务执行。
Later, more complete and efficient support for multi-core processing was further refined with subsequent releases. For instance, Linux version 2.6 provides better task scheduling and load balancing by introducing a new scheduling algorithm that is capable of scheduling different tasks in constant time.
后来,在 Linux 的后续版本中,对多核处理的更完整、更高效的支持得到了进一步完善。例如,Linux 2.6 版本引入了一种新的调度算法,能够在恒定时间内调度不同的任务,从而提供了更好的任务调度和负载平衡功能。
Windows
Windows OS began its support for SMP architecture in Windows NT 4.0 in 1996, but it was primarily designed for servers and workstations. Windows XP released in 2000 is the first Windows system to actually and directly support multi-core. It was optimized to take advantage of multi-core processors.
Windows 操作系统于 1996 年在 Windows NT 4.0 中开始支持 SMP 架构,但当时它主要为服务器和工作站设计。2000 年发布的 Windows XP 是第一个真正直接支持多核的 Windows 系统。它针对多核处理器的优势进行了优化。
In 2010, Microsoft introduced .NET Framework 4.0, which brought an important new feature called Parallel Language Integrated Query, or PLINQ. PLINQ allows developers to write parallel queries in Language Integrated Query (LINQ). It also enabled automatic parallelization of certain LINQ queries. PLINQ is able to distribute the workload across multiple cores automatically, without requiring explicit threading code from the developer. This enables Windows to take full advantage of the parallel processing power of the multi-core architecture.
2010 年,微软推出了 .NET Framework 4.0,它带来了一项重要的新功能,即并行语言集成查询(PLINQ)。PLINQ 允许开发人员使用语言集成查询(LINQ)编写并行查询。它还实现了某些 LINQ 查询的自动并行化。PLINQ 能够在多个内核之间自动分配工作负载,而不需要开发人员编写明确的线程代码。这使得 Windows 能够充分利用多核架构的并行处理能力。
macOS
The first version of macOS to officially support SMP was Mac OS X Server 1.0, released in 1999. Mac OS X Server 1.0 was based on the Mach kernel and BSD Unix, which provided a solid foundation for supporting SMP configurations. It offered true symmetric multiprocessing capabilities, allowing multiple cores to execute tasks concurrently.
第一个正式支持 SMP 的 macOS 版本是 1999 年发布的 Mac OS X Server 1.0。Mac OS X Server 1.0 基于马赫内核和 BSD Unix,为支持 SMP 配置奠定了坚实的基础。它提供了真正的对称多处理功能,允许多个内核同时执行任务。
In 2009, Apple released MacOS Snow Leopard. It introduced a feature called Grand Central Dispatch, or GCD. GCD is able to optimize application performance on multi-core processors and symmetric multiprocessing systems by giving more authority over threads to the operating system. With the help of GCD, developers can easily take advantage of multi-core processors without having to focus heavily on architecture of the operating system’s thread pool.
2009 年,苹果公司发布了 MacOS Snow Leopard。它引入了一项名为 Grand Central Dispatch (GCD) 的功能。GCD 通过赋予操作系统对线程更多的权限,能够优化多核处理器和对称多处理系统上的应用程序性能。在 GCD 的帮助下,开发人员可以轻松利用多核处理器的优势,而不必过多关注操作系统线程池的架构。
3.3 A Detailed Description on How Linux Utilizes Multi-core Processors
Linux 操作系统如何利用多核处理器的详细介绍
Linux, as an open source OS, has a wealth of experience and flexible design in supporting multi-core processors, which is mainly based on its SMP architecture, which allows multiple cores to share the same memory space and the exact same I/O bus. In addition to this, there are also a number of features in Linux that further strengthens Linux’s ability to utilize multiple cores:
作为开放源码操作系统,Linux 在支持多核处理器方面拥有丰富的经验和灵活的设计,这主要基于其 SMP 架构,该架构允许多个内核共享相同的内存空间和完全相同的 I/O 总线。除此之外,Linux 中还有许多功能进一步加强了 Linux 利用多核的能力:
3.3.1 Scheduling Algorithms: CFS (Completely Fair Scheduler)
调度算法: CFS(完全公平调度程序)
CFS is the foundation of Linux’s general task scheduling, focusing on time-sharing for non-real-time processes to ensure fair CPU allocation. It employs a virtual clock system, in which the advancement of each processor’s clock slows with increased task weight. Moreover, each task’s virtual clock is inversely proportional to its weight, effectively measuring CPU time (Liu et al., 2010). CFS replaces the classic priority queue with a red-black tree for each CPU’s run queue, optimizing multi-core scheduling, as shown in Figure 4. High-priority tasks, though slower in virtual time, are scheduled often, promoting resource equity and preventing them from hogging the CPU at the expense of lower-priority tasks, thus improving system performance and responsiveness.
CFS 是 Linux 一般任务调度的基础,侧重于非实时进程的时间共享,以确保 CPU 的公平分配。它采用虚拟时钟系统,每个处理器的时钟前进速度随着任务权重的增加而减慢。此外,每个任务的虚拟时钟与其权重成反比,从而有效测量 CPU 时间(Liu 等人,2010 年)。如图 4 所示,CFS 为每个 CPU 的运行队列设计了红黑树,取代了传统的优先级队列,优化了多核调度。高优先级任务虽然在虚拟时间上较慢,但经常被调度,促进了资源公平,避免了高优先级任务占用 CPU 而牺牲低优先级任务,从而提高了系统性能和响应速度。

In addition to CFS, Linux offers several other scheduling policies, including:
除 CFS 外,Linux 还提供其他几种调度策略,它们包括:
SCHED_FIFO
A FIFO real-time scheduling policy suitable for tasks that require strict timing guarantees.
一种先进先出的实时调度策略,适用于需要严格时间保证的任务。
SCHED_RR
A Round-Robin realtime scheduling policy that allocates a fixed time slice to each task, ideal for tasks that require a higher priority but do not need to monopolize the CPU (Ishkov, 2015).
一种 Round-Robin 实时调度策略,它为每个任务分配固定的时间片。这非常适合需要较高优先级但不需要垄断 CPU 的任务(Ishkov,2015 年)。
SCHED_OTHER
A non-realtime time-sharing scheduling policy designed for regular user-level processes.
为常规用户级进程设计的非实时分时调度策略。
SCHED_IDLE
A low-priority scheduling policy that runs only when no other higher priority tasks require the CPU.
低优先级调度策略,只有在没有其他更高的优先级任务需要 CPU 时才运行。
3.3.2 Time Slicing
时间切片
Linux employs CFS for time slicing, allocating CPU time to processes in a round-robin fashion. This ensures fair execution opportunities for all processes, enhancing system responsiveness and interactivity in a multitasking setting.
Linux 采用 CFS 进行时间切片,以循环方式为进程分配 CPU 时间。这确保了所有进程的公平执行机会,提高了多任务环境下的系统响应速度和交互性。
3.3.3 Thread-level Parallelism
线程级并行
As mentioned above, Linux provides a POSIX-standard kernel level multithreading library called LinuxThreads, which enables user programs to efficiently create, manage, and synchronize threads. These threads benefit from shared memory, which facilitates efficient communication and enhances application performance. Moreover, Linux supports CPU affinity, allowing for the optimization of thread execution on designated cores, reducing cache misses and inter-core communication costs, and effectively make use of the power of multi-core processors to improve overall system efficiency.
如本文此前所述,Linux 提供了一个名为 LinuxThreads 的 POSIX 标准内核级多线程库,它能让用户程序有效地创建、管理和同步线程。这些线程受益于共享内存,从而促进了高效通信并提高了应用程序性能。此外,Linux 支持 CPU 亲和性,允许在指定的内核上优化线程执行,减少缓存缺失和内核间通信成本,有效利用多核处理器的能力,提高整体系统效率。
4 Challenges and Considerations in Multi-Core Processor Scalability
多核处理器可扩展性的挑战和思考
4.1 Limitations of Cores
内核的局限性
Multi-core processors, with their ability to run multiple tasks simultaneously, have changed the field of computing. Each core in these processors perform as an individual, thus adding power for calculating. However, their rise has led issues like cache consistency, memory access patterns and inter-core communication.
多核处理器能够同时运行多个任务,改变了计算领域。这些处理器中的每个内核都能单独运行,从而增加了计算能力。然而,多核处理器的兴起也带来了一些问题,如缓存一致性、内存访问模式和内核间通信。
Cache consistency is about making sure that changes to shared data are correctly updated for anyone who needs that. When a cache copy undergoes a memory writing operation, the cache controller invalidates the copy of data, suggesting a new value has to be fetched from the main memory in the next memory access (Park et al., 1998).
高速缓存一致性是指确保共享数据的更改能正确更新给需要的人。当高速缓存副本进行内存写入操作时,高速缓存控制器会使数据副本失效,这表明在下一次内存访问时必须从主内存中获取新值(Park 等人,1998 年)。
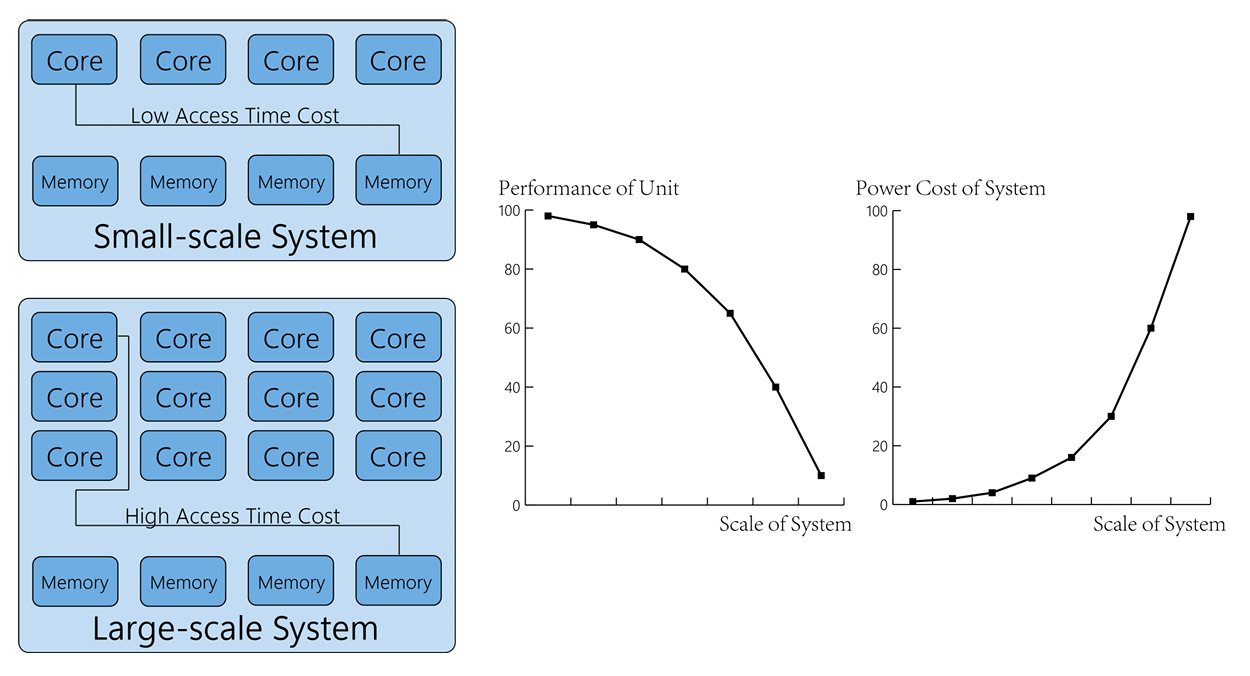
Memory access latency is another issue. Even though processors are equipped with multiple instruction execution units, memory access causes cache misses, which slows down the program considerably. Figure 5 indicated that the physical distances increases as system goes large.
内存访问延迟是另一个问题。尽管处理器配备了多个指令执行单元,但内存访问仍会导致缓存缺失,从而大大降低程序的运行速度。图 5 显示,物理距离随着系统规模的扩大而增加。
The inter core communication also plays a crucial role in CPUs. The compiler should balance float and integer instructions, allowing the scheduling unit keeping all types of units busy. Better algorithm for compiler to optimally schedule instructions can lead to higher performance of CPU.
内核间通信在 CPU 中也起着至关重要的作用。编译器应平衡浮点指令和整数指令,让调度单元保持所有类型单元的忙碌状态。编译器采用更好的算法来优化指令调度,可以提高 CPU 性能。
More cores do not always bring better performance. Overcoming these challenges is essential for true scalability when we increase the number of cores in a single processor.
更多的内核并不总能带来更好的性能。当我们增加单个处理器的内核数量时,克服这些挑战对于实现真正的可扩展性至关重要。
4.2 Limitations of Algorithms
算法的局限性
Parallel programming and thread-level parallelism are of great importance to harnessing the capabilities of super-scalar architecture. Parallel programming allows concurrent computations, improving efficiency and speed.
并行编程和线程级并行对于利用超标量架构的能力非常重要。并行编程允许并发计算,提高了效率和速度。
On the other hand, thread-level parallelism involves different threads executing a single process simultaneously. This is possible benefit from the multiple execution units in a super-scalar processor, which can process separate threads concurrently, enhancing throughput and performance.
另一方面,线程级并行涉及不同线程同时执行单个进程。这可能得益于超标量处理器中的多个执行单元,它们可以同时处理不同的线程,从而提高吞吐量和性能。
However, developing software that can effectively use these features is complex. Developers must consider synchronization, which coordinates the execution of multiple instructions. Poorly managed synchronization can create performance bottlenecks.
然而,开发能有效利用这些特性的软件非常复杂。开发人员必须考虑同步问题,因为同步可以协调多条指令的执行。同步管理不善会造成性能瓶颈。
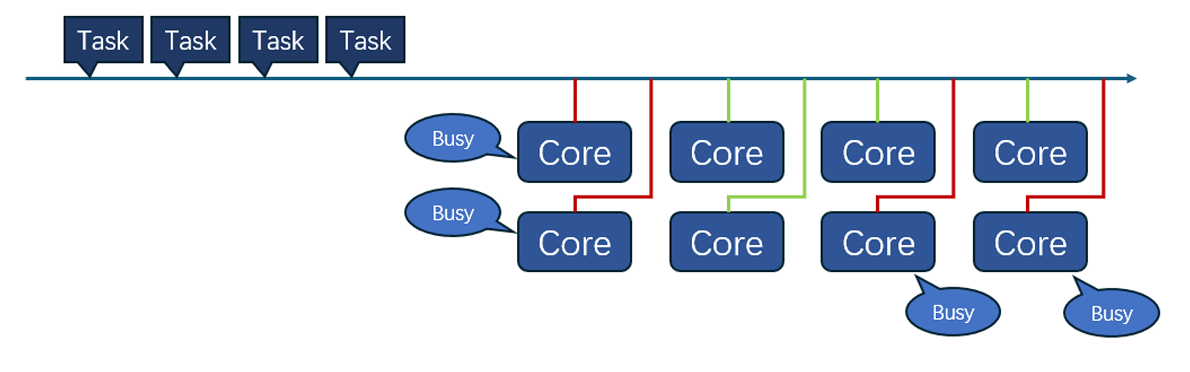
Load balancing, which involves distributing instructions evenly among functional units, is a vital aspect. It is essential to employ dynamic instruction dispatching algorithms to ensure a balanced computational load on units. Uneven distribution can result in either under-utilization or over-utilization of resources, finally impacting system performance. Figure 6 gives a brief sketch of how tasks were distributed to cores.
负载平衡涉及在功能单元之间平均分配指令,这也是一个重要方面。必须采用动态指令调度算法,以确保各单元的计算负载平衡。分配不均可能导致资源利用不足或过度利用,最终影响系统性能。图 6 简要说明了如何将任务分配给内核。
Additionally, effective management of competition for shared resources such as registers and caches is crucial too. In super-scalar architecture, multiple execution units compete for these shared resources, potentially causing bottlenecks of calculating strength.
此外,有效管理对寄存器和缓存等共享资源的竞争也至关重要。在超标量架构中,多个执行单元争夺这些共享资源,有可能造成计算能力瓶颈。
Although parallel programming and thread-level parallelism offer significant advantages, they also come with distinct challenges. Successfully addressing these challenges necessitates meticulous handling of synchronization, load balancing, and resource contention.
尽管并行编程和线程级并行性具有显著优势,但它们也带来了独特的挑战。要成功应对这些挑战,就必须细致地处理同步、负载平衡和资源争用等问题。
4.3 Trade-offs on Designing
设计上的权衡
In the context of super-scalar architecture, there are several trade-offs to consider. One of the key principles is Amdahl’s law, which states that even if parallelized, some parts of the application are still continuous. Amdahl’s law assumes that the speed-up ratio of parallelization is limited by the part of the program that cannot be parallelized (Wu et al., 2011). This means that no matter how many cores are added to the processor, some programs cannot take advantage of this parallelism, which limits the overall acceleration that can be achieved.
在超标量架构中,需要考虑几种权衡。其中一个关键原则是阿姆达尔定律,即即使并行化,应用程序的某些部分仍然是连续的。阿姆达尔定律假定,并行化的提速比例受限于程序中无法并行化的部分(Wu 等人,2011 年)。这意味着,无论处理器增加多少内核,有些程序都无法利用并行化的优势,从而限制了可实现的整体加速。
On the other hand, Gustafson’s Law highlights that as the size of a problem grows, the significance of the parallel aspect also increases to enhance scalability. According to this principle, with the availability of more computing resources, they are typically allocated to tackle larger problems. In this scenario, the time spent on the parallelizable segment is often considerably faster than the inherent serial tasks.
另一方面,古斯塔夫森定律强调,随着问题规模的扩大,并行方面的重要性也会增加,从而提高可扩展性。根据这一原理,随着更多计算资源的可用性,这些资源通常会被分配用于解决更大的问题。在这种情况下,花在可并行化部分的时间往往比固有的串行任务快得多。
This means that designing better method and algorithm to realize functions and turn sequential computing into parallel computing will also help improve scalability. Interestingly, slower algorithms that can run in parallel sometimes work better on faster sequential algorithms on multi-core processors.
这意味着,设计更好的方法和算法来实现功能并将顺序计算转化为并行计算,也将有助于提高可扩展性。有趣的是,在多核处理器上,可以并行运行的较慢算法有时会比较快的顺序算法运行得更好。
Finding the right balance is not easy. It’s important to handle parallel tasks, synchronization, and communication overhead carefully. In super-scalar processors, problems like delays become more obvious and can affect performance. This can lead to scheduling issues. So, when creating super-scalar architecture, it’s crucial to think about these factors carefully.
找到正确的平衡并不容易。谨慎处理并行任务、同步和通信开销非常重要。在超标量处理器中,延迟等问题变得更加明显,并可能影响性能。这可能会导致调度问题。因此,在创建超标量架构时,仔细考虑这些因素至关重要。
5 Conclusion
结论
The evolution of multi-core processors and multi-processor PCs has revolutionized the hardware landscape, while advancements in operating systems have adapted to harness this increased processing power, illustrating the symbiotic relationship between hardware and software in the journey towards more efficient computing.
多核处理器和多处理器个人电脑的发展彻底改变了硬件的面貌,而操作系统的进步也适应了这种处理能力的提高,这说明了在实现更高效计算的过程中硬件和软件之间的共生关系。
The future of computing may be dominated by multi-core processors, with more and more emphasis on hardware and software level parallelism. There are undoubtedly still many challenges in this field, but we can still look forward to the future development of super-scalar architectures.
未来的计算可能由多核处理器主导,硬件和软件层面的并行性将越来越受到重视。毫无疑问,这一领域仍存在许多挑战,但我们仍可期待超标量架构的未来发展。
6 References
参考文献与资料
This reference list is in Harvard style.
本参考文献与资料列表采用 Harvard 风格。
If you intend to cite these sources in your writing, be sure to pay attention to the reference style accepted by your academic institution or the conference/journal to which you intend to submit.
如果您有意在您的写作中引用这些参考文献与资料,请务必注意您的学术机构,或您打算提交的会议/期刊所接受的参考文献风格。
Amazon (2023) GEEKOM Mini PC Mini IT13, 13th Gen Intel i9-13900H NUC13 Mini Computers(14 Cores, Threads) 32GB DDR4 & 2TB PCIe Gen 4 SSD Windows 11 Pro Desktop PC Support Wi-Fi 6E/Bluetooth 5.2/USB 4.0/2.5G LAN/8K. Available at: https://www.amazon.com/GEEKOM-Mini-IT13-i9-13900H-Computers/dp/B0CJTGHNV2 (Accessed: 13 April 2024).
Chen, G.L., Sun, G.Z., Xu, Y. and Long, B. (2009) ‘Integrated research of parallel computing: Status and future’, Science Bulletin, 54(11), pp. 1845-1853. Available at: https://link.springer.com/article/10.1007/s11434-009-0261-9. (Accessed: 14 April 2024).
Ishkov, N. (2015) ‘A complete guide to Linux process scheduling (Master’s thesis)’, M.Sc. Thesis. Available at: https://trepo.tuni.fi/bitstream/handle/10024/96864/GRADU-1428493916.pdf?sequence=&isAllowed=y (Accessed: 15 April 2024).
Liu, T., Wang, H.J., Wang, G.H. (2010) ‘Research of CFS Scheduling Algorithm Based on Linux Kernel’, Computer & Telecommunication , 4(3), pp. 61-63. Available at: https://qikan.cqvip.com/Qikan/Article/Detail?id=33544743&from=Qikan_Search_Index (Accessed: 16 April 2024).
Park, G.H., Kwon, O.Y., Han T.D., Kim, S.D. and Yang S.B. (1998) ‘Methods to improve performance of instruction prefetching through balanced improvement of two primary performance factors’, Journal of Systems Architecture, 1998(9), pp. 755-772. (Accessed: 17 April 2024).
Wu, X.L., Beissinger, T.M., Bauck S., Woodward, B., Rosa G.J.M., Weigel, K.A., Gatti, N.L. and Gianola, D. (2011) ‘A Primer on High-Throughput Computing for Genomic Selection’, Frontiers in Genetics. (Accessed: 16 April 2024).
Accessing
获取本文章
Click the “Download” button below to download this article (in PDF, English).
请点击下方的 “Download” 按钮下载本文章(PDF 格式,英文)。
Unless otherwise stated, all posts from WaterCoFire are licensed under:
WaterCoFire 的所有内容分享除特别声明外,均采用本许可协议:
CC BY-NC-SA 4.0
Reprint with credit to this source.
转载请注明本来源,谢谢喵!